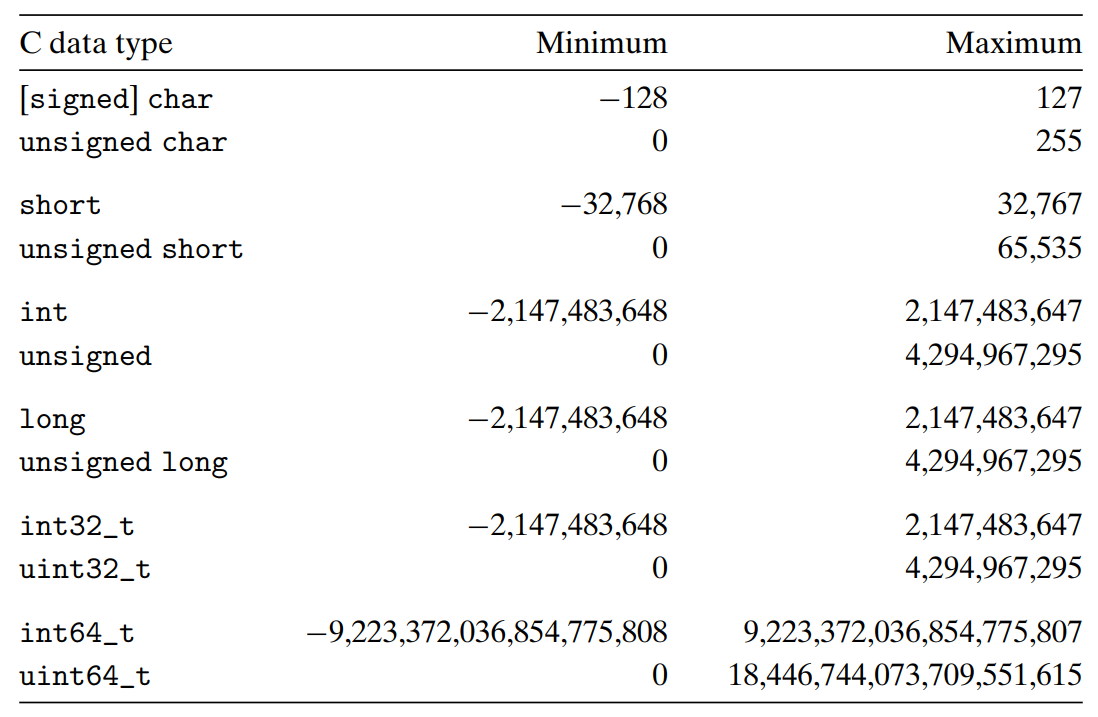
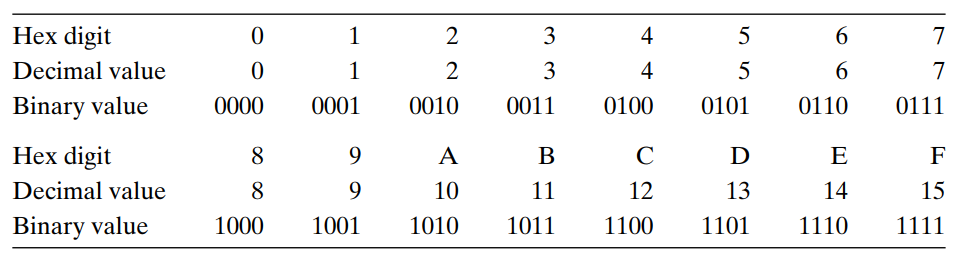
2.0 Intro 이 절에선 정수를 인코딩하기 위해 사용할 수 있는 두 가지 방법 (양수만 표시할 수 있는 방법과, 음수, 0, 양수 모두를 표시할 수 있는 방법) 에 대해 설명한다. 나중에 이들이 수학적 특성, Low-Level 수준을 볼 때 매우 연관되어있음을 알게 될 것이다. 그리고 인코딩된 정수를 다른 길이의 표현에 맞도록 조절하기 위해 확장하거나 축소하는 효과에 대해서도 살펴본다. 2.1 정수형 데이터 타입 2.1.1 C의 다양한 정수형 데이터 타입 아래 두 그림에는 전형적인 32bit와 64bit 프로그램들에서 이들이 갖는 값의 범위를 나타내었다. 각 타입은 unsigned로 선언되어 표시된 숫자가 모두 양수인지, 아니면 기본타입으로 음수도 나타낼 수 있는지 뿐만 아니라 키워드 char, sh..