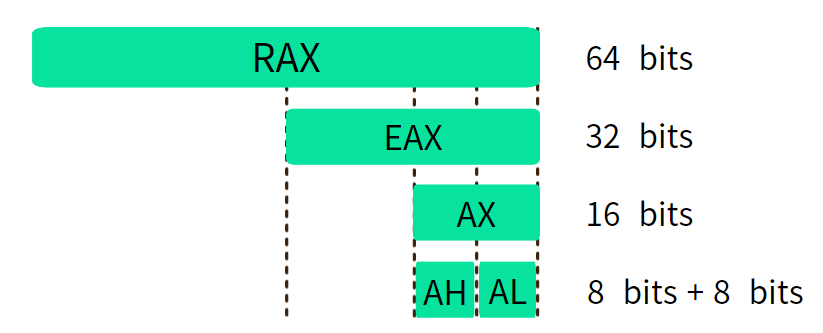
기기별 운영체제 점유율 우리가 인지하지 못하는 사이 리눅스는 우리 생활을 이루고 있습니다.이번 시간에는 전 세계에서 IT 각 기기별로 리눅스 운영체제를 얼마나 쓰는지 알아보겠습니다. - 데스크탑(PC)- 휴대폰 - 슈퍼컴퓨터 1. 데스크탑 PC 운영체제 점유율 먼저 다음 그림을 보면서 데스크탑 PC 운영체제 점유율을 확인해봅시다.[출처: http://gs.statcounter.com/os-market-share/desktop/worldwide] 위 그래프 가장 윗부분에 Microsoft ‘윈도우 NT 계열’ 운영체제가 73.31% 점유율로 부동의 1위를 지키고 있습니다. 그다음으로 iOS가 15.45% 그리고 리눅스는 4.5% 점유율을 보입니다. 유닉스 계열 운영체제로 분류되는 iOS와 리눅스..