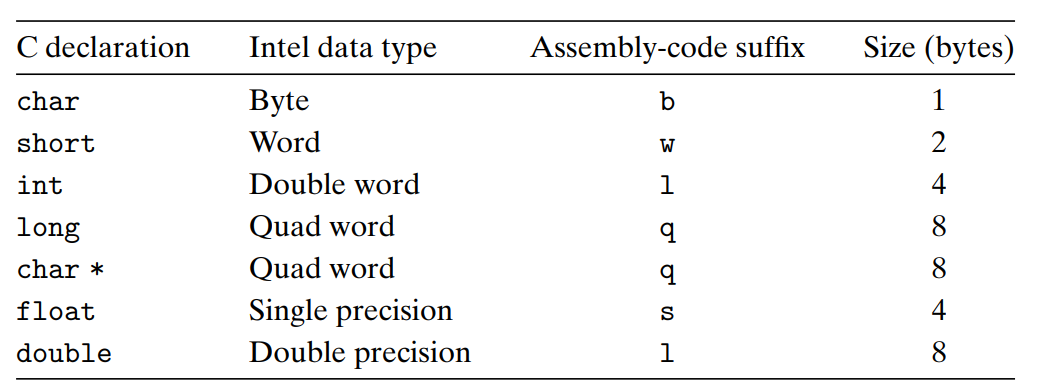
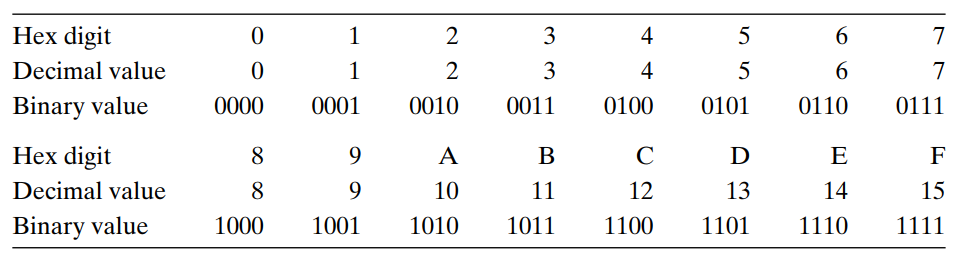
3.3 데이터의 형식 인텔 프로세서들이 처음에는 16비트 구조를 사용했기 때문에, 워드라는 단어를 16비트 데이터 타입을 말할 떄 사용한다. 32비트는 '더블워드' , 64비트는 '쿼드워드' 라고 부른다. • 포인터 : 64bit 머신에선 예상대로 8byte 쿼드워드로 저장됨. • 부동소수점 : x86계열에서 특별히 10byte 부동소수점 형식 연산을 구현하였으나, 호환성과 성능을 고려하여 이용하지 않는 것이 좋다. 여기서 주목할 점은, 포인터 char * 은 쿼드워드로 표현된다는 것 → 모든 포인터가 다 q로 표현된다. 이 데이터의 형식이 각 인스트럭션의 접미사로 붙여쓰이게 된다. 예를 들면 movb (바이트이동), movw (워드이동), movl (더블워드 이동), m..