Ⅱ. 정보의 표현과 처리
2.0. Intro
현대의 컴퓨터는 두 개의 값을 갖는 신호로 표현되는 정보를 저장하고 처리한다. 이진수인 비트는 디지털 혁명의 근원인다. 이 비트들을 묶어서 가능한 다른 비트 패턴에 의미를 부여하도록 특정 해석방법을 적용하면(PCM), 어떤 유한집합의 원소들을 표시할 수 있게 된다.
이 장에서는 세 개의 가장 중요한 숫자 표현에 대해 살펴본다.
비부호형 인코딩 : 어떤 연산의 경우에는 그 결과값이 표시할 수 없을 정도로 커서 오버플로우를 발생시킬 수 있다.
2의 보수 인코딩 : 양수, 또는 음수값을 같는 부호형 정수를 표시하는 가장 일반적인 방법이다.
예상된 결과를 컴퓨터가 만들어 내지 않았을지는 몰라도, 적어도 일관된 결과를 만든다.
부동소수점 인코딩 : 2진수 버전의 소수를 표시하기 위한 과학적인 방법이다. 정수 표현은 비교적 작은 범위의 값을 매우 정밀하게 하는 반면, 부동소수점 표시는 넓은 범위의 값을 근사값으로만 인코딩해야 한다.
실제 수의 표시방법을 학습하면서 표시 가능한 값의 범위와 여러 산술연산의 특성을 이해할 수 있다. 이러한 점들에 대해서 이해하게 되면 모든 범위의 숫자들에 있어서도 정확히 동작하고 다양한 컴퓨터, 운영체제, 컴파일러 조합에도 동일하게 동작하는 프로그램을 작성할 수 있게 된다.
2.1 정보의 저장
메모리에 저장된 각 비트들을 접근하는 방식 대신, 컴퓨터는 메모리에서 주소지정이 가능한 최소단위인 8비트 단위의 블록인 바이트를 사용한다. 어셈블리 코드는 메모리를 가상메모리라고 하는 거대한 바이트의 배열로 취급한다.
메모리의 각 바이트는 주소라고 하는 고유한 숫자로 식별할 수 있으며, 가능한 모든 주소들의 집합을 '가상 주소공간'이라 부란다. (기계수준 프로그렘에게 제공되는 개념적인 이미지에 불과함)
이 메모리 공간을 보다 관리하기에 적합한 크기로 분할해서 프로그램 데이터, 인스트럭션, 제어정보 등의 여러 프로그램 객체들을 저장하는지에 대해 다루겠다. C 컴파일러는 가상 주소공간에서 타입 정보와 관련하여 포인터가 지시하는 위치에 접근하기 위해 각기 다른 기계수준 코드를 생성할 수 있다. 비록 C 컴파일러가 타입 정보를 관리하지만, 컴파일러가 생성하는 실제 어셈블리 코드는 자료형에 대한 정보를 전혀 가지고 있지 않다. 다만 객체를 단순히 바이트들의 블록으로 취급하고, 프로그램 자신은 바이트의 연속으로 취급한다.
2.1.1 16진수 표시
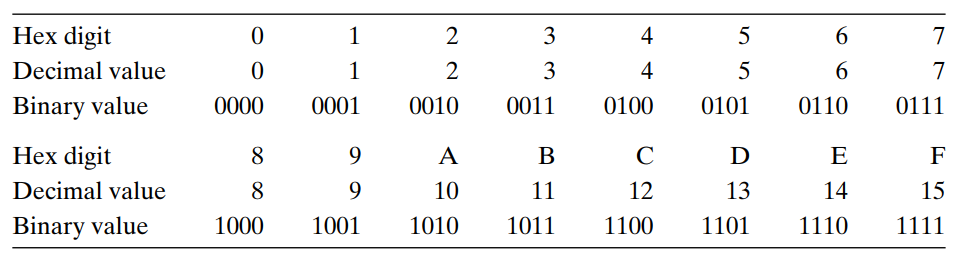
C에서 0x나 OX(zero x)로 시작하는 숫자 상수들은 16진수로 해석한다. 문자 'A'에서 'F'까지는 대문자나 소문자 모두 사용할 수 있다.
2.1.2 데이터의 크기
워드 크기
모든 컴퓨터는 워드 크기(word size)를 규격으로 가지게 되는데, 이는 포인터의 정규 크기를 표시한다. 하나의 가상주소가 이와 같은 한 개의 워드로 인코딩되므로, 워드 크기가 결정하는 가장 중요한 시스템 변수가 가상 주소공간의 최대 크기이다.
64비트 컴퓨터는 대규모 과학계산이나 데이터베이스 응용을 위한 고성능 컴퓨터에서 시작되어, 오늘날에는 스마트폰에서도 사용한다.
호환성
대부분의 64비트 컴퓨터들은 역방향 호환성을 지니어 32비트 머신을 위해 컴파일된 프로그램도 실행할 수 있다.
linux> gcc -m32 prog.c위 처럼 컴파일한 경우 32비트나 64비트 머신 양쪽에서 정확하게 동작한다.
linux> gcc -m64 prog.c이렇게 컴파일한 프로그램은 64비트 머신에서만 정확하게 동작한다.
데이터 타입과 크기
컴퓨터와 컴파일러는 정수와 부도옷수점 같은 데이터를 여러 가지길이뿐만 아니라 서로 다른 인코딩 방법을 사용해서 다중데이터 포멧을 지원한다.
정수뿐만 아니라 하나의 바이트를 처리하는 인스트럭션들을 가지고 있다.
C언어는 정수 데이터는 0과 음수, 양수를 표시하기 위해 부호형(signed) 정수가 되거나, 양수 값만 나타내는 비부호형(unsigned) 정수가 될 수 있다.

일반적인 크기나 서로 다른 컴파일러 설정에 의존해서 발생하는 문제를 피하기 위해, ISO C99는 컴파일러와 컴퓨터 설정에 관계없이 데이터의 크기가 고정된 자료형을 제안하였다. int32_t는 정확히 4바이트, int64_t는 정확히 8바이트와 크기를 갖는다.
위 도표는 프로그램의 워드 크기를 이용하는 포인터(ex. char* 로 선언된 변수)를 보여준다.
대부분의 컴퓨터는 두 종류의 부동소수점 형식을 지원한다.
C에서 float로 선언하는 단일정밀도(4바이트), double로 선언하는 이중정밀도(8바이트)
프로그래머는 자신의 프로그램이 여러 종류의 컴퓨터와 컴파일러에서 동작할 수 있도록 노력해야 한다.
2.1.3 주소지정과 바이트 순서
여러 byte에 걸쳐 있는 프로그램 객체들에, 우리는 두가지 관습을 정해야 한다.
- 객체의 주소가 무엇이 되어야 하는지, 메모리에 byte들을 어떻게 정렬해야 하는지
바이트 순서
객체를 나타내는 바이트를 정렬하는 데에는 두 가지 방법이 있다.
- 가장 덜 중요한바이트부터 메모리에 저장(Little endian), 가장 중요한 바이트부터 저장(Big endian)
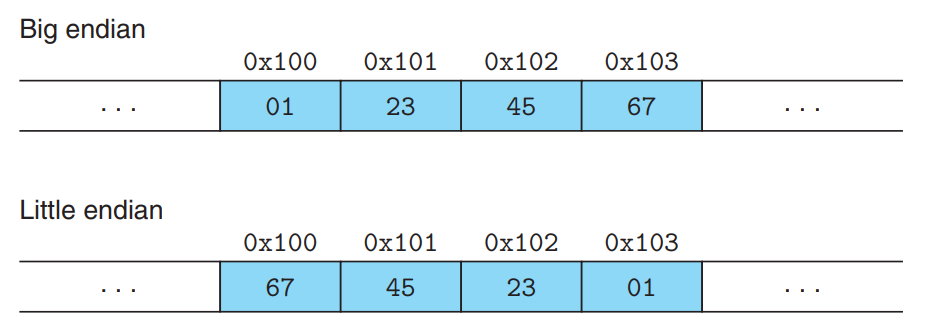
대부분의 인텔 호환 머신은 리틀 엔디안 방식으로만 동작한다.
ARM 프로세서 칩은 리틀 엔디안과 빅 엔디안 둘 다 지원하지만, 모바일 OS인 안드로이드와 iOS는 리틀 엔디안 모드로만 동작한다.
한편, IBM과 Oracle 머신들은 빅 엔디안 방식으로 동작한다.
바이트 순서 이슈
대부분의 응용 프로그래머들에게 바이트 순서는 알 수 없는 것이었다. 그러나 종종 바이트 순서가 이슈가 되기도 한다.
① 이진 데이터가 네트워크를통해 다른 컴퓨터로 전송될 때
- 리틀 => 빅엔디안 머신으로 데이터를 보내, 수신 측에서 바이트 순서가 뒤바뀌는 경우
- 네트워크 응용프로그램으로 작성된 코드는 송신 측 컴퓨터가 내부 표시를 네트워크 표준으로 하고, 수신측 컴퓨터가 네트워크 표준대로 내부 표시방식을 변환하도록 Standard를 따라야 한다.
② 정수 데이터를 나타내는 바이트들을 살펴볼 때 (어셈블리 코드를 조사할 때 종종 발생)
4004d3: 01 05 43 0b 20 00 add %eax, 0x200b43(%rip)- 역 어셈블러는 실행 프로그램 파일의 인스트럭션을 결정하는 도구이다.
- 간단히, 16진수 byte 01 05 43 0b 20 00 들이 워드 크기의 데이터를 현재 프로그램 카운터 값에 0x200b43을 더해서 계산된 주소에 저장된 값을 더하는 파이트-수준 표시.
- 마지막 4바이트 43 0b 20 00을 역순으로 쓰면 우측의 0x200b43을 얻게 된다.
③ 프로그램이 정상적인 자료형(type) 체계를 회피하도록 작성되었을 때
- C언어데서 캐스트(cast)나 유니온(union)을 사용하여, 객체가 만들어졌을 때와는 다른 타입의데이터로 참조될 수 있도록 한 수 있다.
- 응용 프로그램 작성시에는 엄격히 제한해야하지만, 시스템 프로그램에서는 상당히 유용하고 꼭 필요하기까지 하다.
2.1.4 스트링의 표시
show_bytes
C에서 가장 일반적인 인코딩이 ASCII 코드이다. 만일 show_bytes를 "12345"와 6(종류문자까지 포함)을 인자로 실행하면 33 34 35 00을 출력한다.
ASCII를 문자코드로 사용하는 모든 컴퓨터에서 바이트 순서나 워드 크기와 무관하게 똑같이 얻을 수 있다.
(Text data는 binary data보다 플랫폼 독립적이다.)
2.1.5 코드의 표현

위와 같은 C 함수를 컴파일하면, 아래와 같은 byte 표시를 갖는 어셈블리 코드를 생성한다.
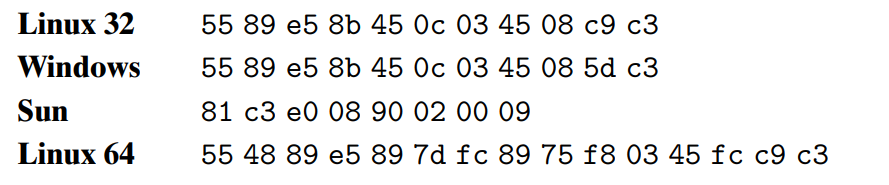
인스트럭션들의 인코딩이 모두 다르다는 것을 알 수 있다. 서로 다른 머신, 심지어 서로 다른 OS에도 호환성이 없고 각기 다른 인스트럭션과 인코딩을 사용한다.
binary code는 컴퓨터와 운영체제들의 여러가지 조합들 간에 오환성을 갖는 경우가 드물다.
2.1.6 부울 Boolean 대수
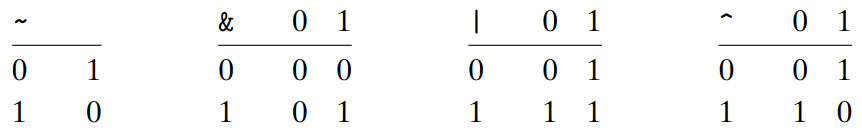
2.1.7 C에서의 비트수준 연산

2.1.8 C에서의 논리 연산
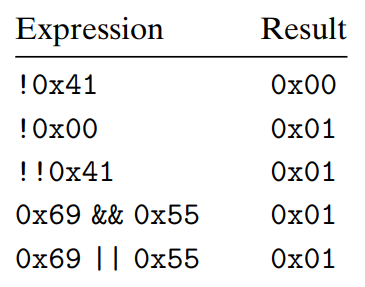
논리 연산과 비트단위 연산의 비교
① 인자들이 0이나 1로 제한되는 경우에만 비트단위 연산과 논리 연산이 동일하게 동작한다.
② 논리연산자들은 수식의 결과가 첫 번째 인자를 계산해서 결정할 수 있으면, 두 번째 인자는 계산하지 않는다.
- 식 [ a && 5/a ]는 0으로 나누기 오류를 절대 발생시키지 않고, 식 [ p && *p++ ]은 널 포인터의역참조를 절대 발생시키지 않는다.
2.1.9 C에서의 쉬프트 연산
C에서의 x << k
좌측 쉬프트 : x는 좌측으로 k비트 이동하고, 중요한 좌측의 k비트가 밀려 삭제되며, 우측에는 '0'이 k개만큼 채워진다.
C에서의 x >> k
논리 우측 쉬프트 : 좌측 끝에 '0'이 k개만큼 채움.
산술 우측 쉬프트 : 좌측 끝을 '가장 중요한 비트'를 k개 반복하여 채움. (부호형 정수 데이터의 연산에 유용하게 작용됨)
C 표준은 부호형 숫자의 경우에 어떤 타입의 우측 쉬프트가 사용해야 하는지 명확히 정의내리고 있지 않다.
Java에서의 우측 쉬프트
자바는 [ x >> k ]는 산술적으로 k만큼 위치 쉬프트하지만, [ x >>> ]는 논리적으로 쉬프트한다.
'Fundamental of CS > : : CSAPP' 카테고리의 다른 글
| [CSAPP] Ch 3. 프로그램의 기계수준 표현 : (3) 데이터의 형식 (0) | 2024.03.19 |
|---|---|
| [CSAPP] Ch 3. 프로그램의 기계수준 표현 : (2) 프로그램의 인코딩 (0) | 2024.03.19 |
| [CSAPP] Ch 3. 프로그램의 기계수준 표현 : (1) 역사적 관점 (0) | 2024.03.19 |
| [CSAPP] Ch 2. 정보의 표현과 처리 : (2) 정수의 표시 (0) | 2023.12.14 |
| [CSAPP] Ch 1. Prologue : A Tour of Computer System (0) | 2023.10.18 |