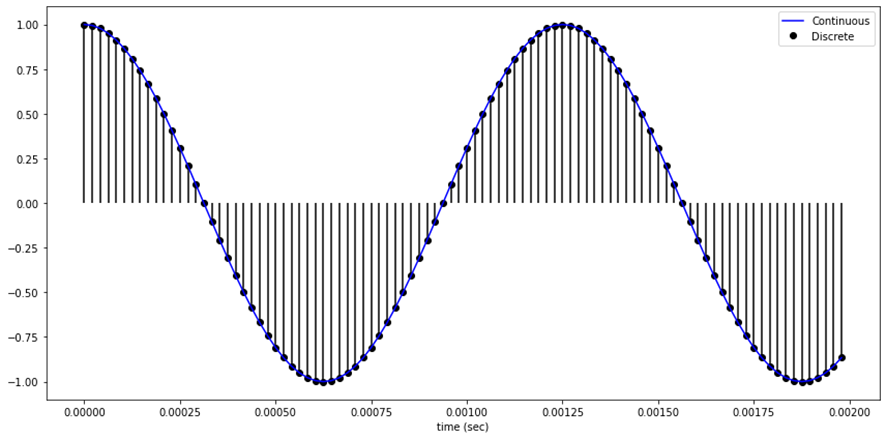
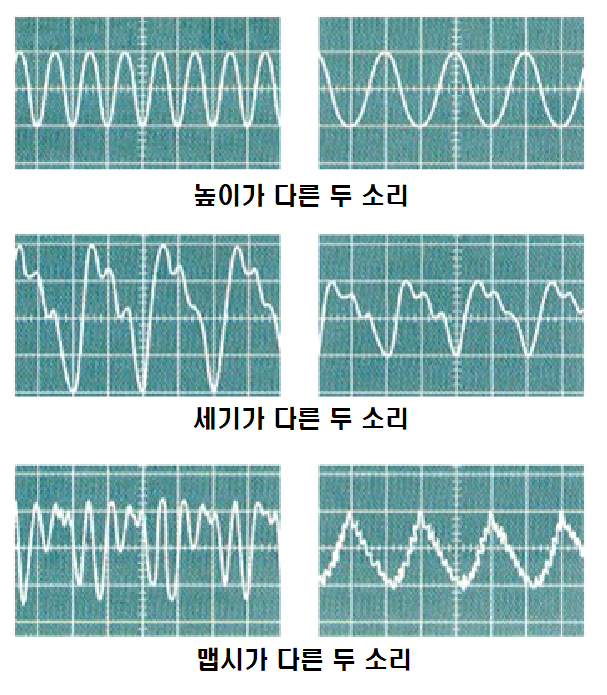
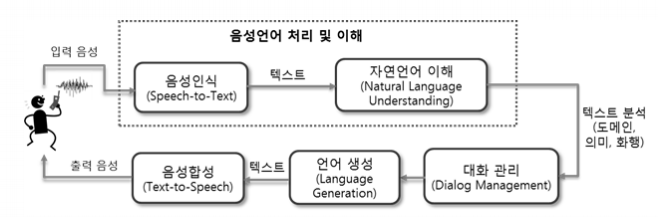
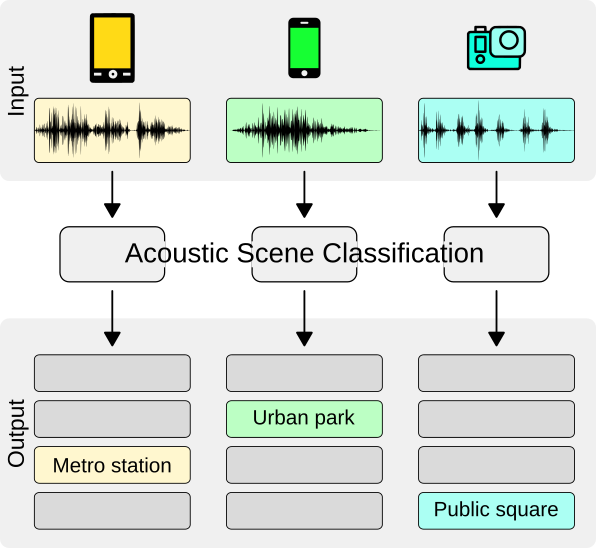
표본화(Sampling) 소리는 연속적인 데이터이다. 소리 데이터를 컴퓨터에 저장하기 위해서는 Sampling과 Quantization을 통해 discrete하게 표현해야 한다. 먼저, 실수형태인 시간을 저장하기 위해 sampling을 진행한다. □ Sampling이란 시간을 이산적인 구간으로 나누는 것이다. 즉, 샘플링 간격에 따라 amplitude를 측정하는 것이다. 1초의 연속적인 신호를 몇개의 숫자들의 sequence로 표현할 것인가를 sampling ratefs이다. sampling rate가 클수록 즉, 자주 sampling할 수록 원본 데이터와 비슷할 것이다. 그러나 그만큼 저장해야 하는 데이터의 양이 늘어나게 된다. sampling rate가 작게 되면 아래와 같이 aliasing이 일어..