KNN (K-Nearest Neighbor)
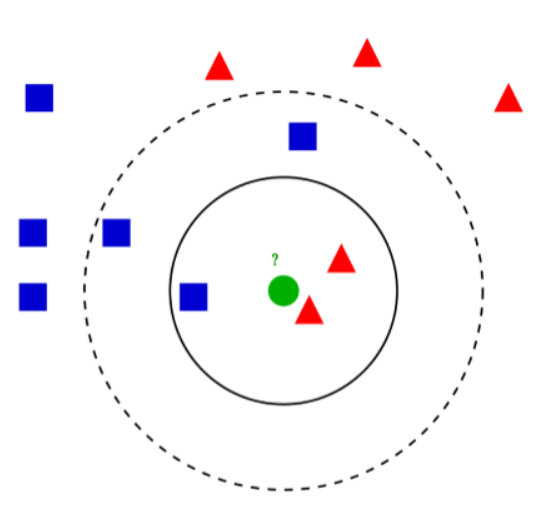
0. Intro KNN이란 k의 개수만큼 주변의 샘플 정보를 이용해서 새로운 관측치의 종속변수(y값)을 예측하는 지도학습 1. KNN (K-Nearest Neighbor) 1.1 KNN (K-Nearest Neighbor) ? 위 그림에서, 빨간색과 파란색의 종속변수의 범주가 있습니다. 일반적으로, 새로운 관측치인 녹색을 분류해야 하는데, 실선으로 k가 3일 때에는 빨강으로, 점선으로 k가 5일 때에는 파란색으로 판별합니다. 가까운 곳에 위치한 것에 따라 가중치(Weight)를 많이 주는 방법도 있습니다. 그리고, KNN은 종속 변수가 어떻게 되는가에 따라 방법이 달라집니다. 범주형 변수의 경우 가장 많이 나타나는 범주로 y를 추정하고, 연속형 변수의 경우 KNN의 평균으로 y를 추정합니다. 중요한 것은..